Archivage de données
Le Web et les technologies informatiques en général sont en constante évolution. Comment préserver les données qui sont importantes pour notre recherche ou notre activité professionelle ? Au cours de cette session, nous présenterons des stratégies et des bonnes pratiques pour la préservation des données.
Chaire de recherche du Canada sur les écritures numériques, Bibliothèque des lettres et des sciences humaines, Ouvroir d'histoire de l'art et de muséologie numérique. — giulia.ferretti@umontreal.ca ; louis-olivier.brassard@umontreal.ca
Plan de la séance
- Introduction
- Qu’est-ce que Wget ?
- Installation
- Premier téléchargement avec Wget
- Télécharger des images en vrac avec Wget
- Archiver des documents web avec Wget
- Conclusion
0. Introduction
Internet donne accès à une quaisi-infinité de contenus, disponibles sur demande vingt-quatre heures par jour, chaque jour de l’année. Comme c’est pratique !
… jusqu’au jour où ce n’est plus vrai : bande passante au ralenti ou connexion coupée, site web en maintenance ou hors service, archives disponibles uniquement par VPN ou depuis une adresse autorisée, etc. Les raisons deviennent soudainement de plus en plus nombreuses d’assurer un accès aux ressources dont on a besoin pour travailler, comme une base de données, des images précises ou des textes particuliers. Bref, il faut une stratégie d’archivage.
Pour y parvenir, nous vous proposons aujourd’hui un outil : wget !
1. Qu’est-ce que Wget ?
wget est un logiciel qui fonctionne en ligne de commande.
Il permet d’effectuer des téléchargements avec diverses options et protocoles.
Nous verrons en quoi ces options peuvent être utiles !
Nous allons nous en servir aujourd’hui pour archiver certains objets d’étude disponibles en ligne, mais que nous souhaitons pouvoir consulter hors connexion.
2. Installation
Si vous utilisez macOS ou Linux, wget est probablement déjà installé.
Vous pouvez vous en assurer en ouvrant une fenêtre de terminal et en entrant :
# cela affichera le message d'aide de wget
wget --helpSur Windows, vous pouvez utiliser Cygwin (émulateur de commandes Unix pour Windows) ou Ubuntu bash sur Windows 10 pour avoir accès à wget.
Vous pouvez aussi télécharger wget directement depuis ce site qui en fait la distribution.
Installation sur Linux
sudo apt install wgetInstallation sur macOS
# avec Homebrew
brew install wget3. Premier téléchargement avec Wget
Nous allons effectuer un premier téléchargement tout simple avec wget.
Par exemple, nous allons archiver l’image d’une toile de l’artiste suprématiste Kasimir Malevitch sur Wikimedia Commons.
Sur la page de l’image Wikimedia Commons, nous allons cliquer sur le bouton « Télécharger ». Dans la boîte de dialogue, plusieurs champs s’offrent à nous :
_-_Suprematist_Painting_(with_Black_Trapezium_and_Red_Square)_(A_7681)_1915.jpg?uselang=fr){kind=link}
- l’URL de la page, qui est la même que celle qui figure dans la barre d’adresse du navigateur ;
- l’URL du fichier, qui est véritablement celle qui nous intéresse ;
- le crédit de l’auteur du fichier, qu’on peut copier en texte brut ou en format HTML.
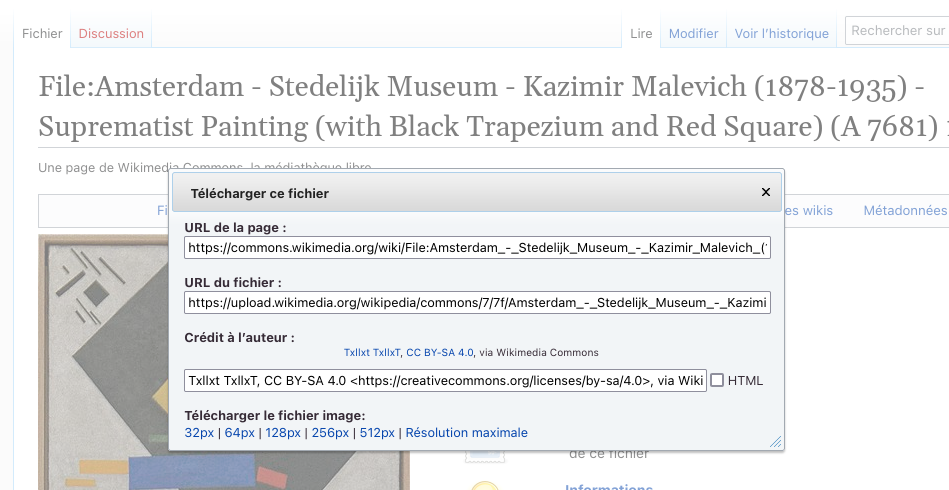
Boîte de dialogue d’un fichier sur Wikimédia Commons
Dans la boîte de dialogue, copier l’URL du fichier, puis le coller dans le terminal, en remplaçant url-du-fichier par la véritable URL :
wget url-du-fichier
# ...
# si tout s'est bien passé, wget devrait avoir téléchargé
# l'image dans le répertoire courant!Nous pouvons examiner le résultat avec la commande ls :
ls
# la console devrait retourner notre fichier téléchargé
# -> Amsterdam_-_Stedelijk_Museum_-_Kazimir_Malevich_...Et la même chose dans notre explorateur de fichiers :
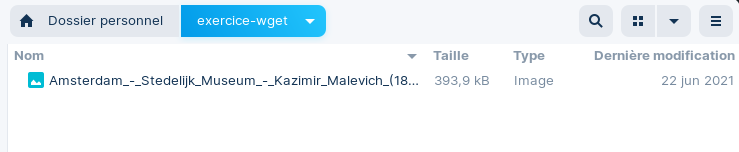
Le fichier que nous venons de télécharger avec Wget
wget !
… mais il est vrai que c’est assez peu excitant (nous aurions pu tout simplement sauvegarder l’image directement depuis la page de Wikmédia Commons).
Examinons un cas où wget s’avérera encore plus utile !
4. Télécharger des images en vrac avec Wget
4.1 Une image unique sur Gallica
De nombreux objets d’étude, comme un livre ou un journal, consistent en une série de plusieurs numérisations – une image pour chaque page numérisée. Nous pouvons tirer parti de ce découpage sur des plateformes comme Gallica pour archiver les pages qui nous intéressent !
Comment pourrions-nous numériser les dix premières pages du roman Une saison en enfer d’Arthur Rimbaud, accessible librement grâce à la plateforme de la BNF ?

Dans le film The Social Network (2010), le personnage de Mark Zuckerberg mentionne l’outil Wget pour récupérer les photos du serveur de son université.
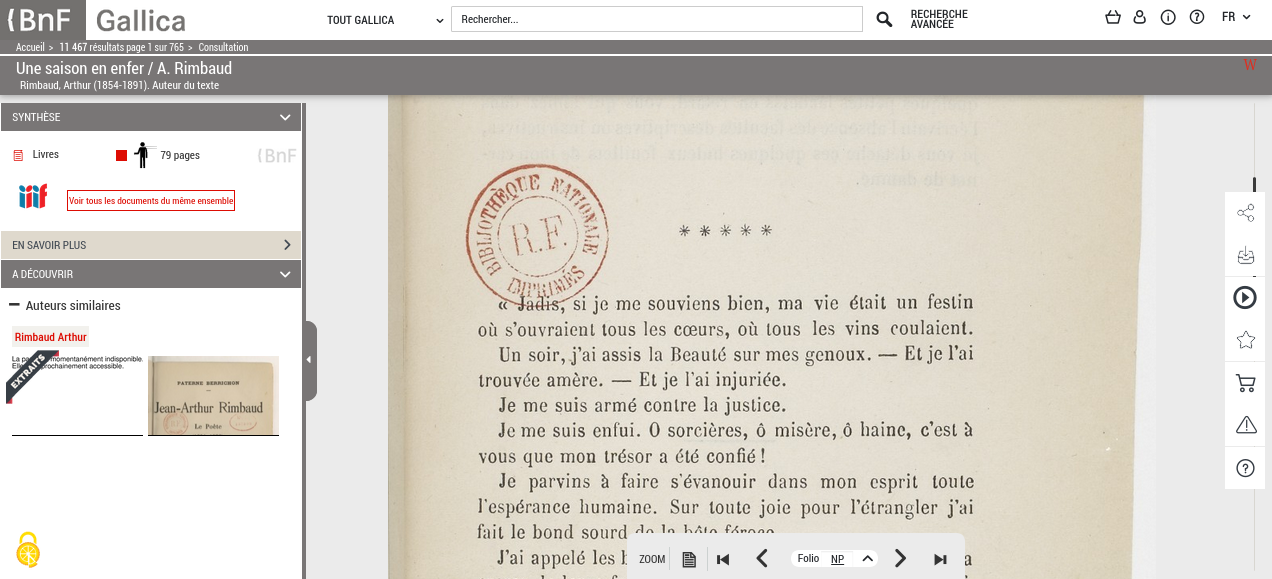
Une saison en enfer d’Arthur Rimbaud, affichage d’un exemplaire disponible sur Gallica.
Dans cet exemple, la nouvelle commence à partir du 13e folio numérisé.
Vous pouvez copier cette URL pour effectuer le téléchargement avec wget :
# créez-vous un dossier de travail et naviguez-y
# 1. creation du dossier
mkdir mon-dossier-pour-apprendre-wget
# 2. se déplacer dans le dossier
cd mon-dossier-pour-apprendre-wget
# on récupère l'image du folio no. 13 avec la commande wget
wget https://gallica.bnf.fr/ark:/12148/btv1b86108277/f13.highres4.3 Télécharger une liste d’images
Nous voulons archiver les 10 premières pages du livre. Nous pourrions poursuivre en répétant la commande wget, mais en incrémentant le numéro de folio (13, 14, …), à la fin de l’URL (...f13.highres) :
wget https://gallica.bnf.fr/ark:/12148/btv1b86108277/f14.highres
wget https://gallica.bnf.fr/ark:/12148/btv1b86108277/f15.highres
wget https://gallica.bnf.fr/ark:/12148/btv1b86108277/f16.highres
# ... et ainsi de suiteNous allons mettre à profit ce que nous avons appris avec la notion de texte brut, ou le format .txt.
wget peut lire une liste d’URLs à partir d’un fichier. On pourrait donc créer un fichier liste-urls.txt qui ressemblerait à ceci :
|
|
-i (ou --input-file) de wget :
# Pour lancer le téléchargement à partir d'une liste dans un fichier
wget -i liste-urls.txtSi vous avez python installé sur votre appareil, essayez l’étape suivante !
4.3 Utilisation d’un script python (optionnel)
Créez un fichier generateur-urls.py. Remplissez-le avec le bloc de code suivant.
|
|
# ce script devrait remplir le fichier `liste-urls.txt`
python generateur-urls.pyOn a ainsi un fichier liste-urls.txt rempli avec tous les folios que nous voulons télécharger.
# on peut examiner le contenu du fichier avec la commande `cat`
cat liste-urls.txtwget :
# la commande wget, avec quelques options
wget \
-i liste-urls.txt \
--limit-rate=100k \
--directory-prefix=rimbaud-une-saison-en-enfer \
--continue
# ...
# pour chaque fichier, wget affichera un état d'avancementtree .
.
├── generateur-urls.py
├── liste-urls.txt
└── rimbaud-une-saison-en-enfer/
├── 13.medres
├── 14.medres
├── 15.medres
├── 16.medres
├── 17.medres
├── 18.medres
├── 19.medres
├── 20.medres
├── 21.medres
├── 22.medres
└── 23.medresLe même résultat, dans l’exploratur de fichiers (interface graphique).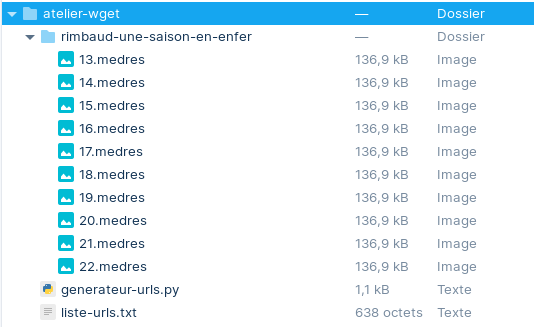
5. Archiver des documents web avec Wget
On peut utiliser wget pour sauvegarder une page web, ou même un site web au complet !
L’option --mirror (ou -m) peut justement être pratique pour créer une « copie miroir » d’un site web localement sur sa machine.
6. Archiver une page web
Télécharger une page html avec wget. Ajouter l’option -P (ou --directory-prefix) pour indiquer le dossier dans lequel la page doit être enregistrée.
-O (ou --output-document) pour changer le nom du fichier.
--adjust-extension pour ajouter une extension appropriée aux fichiers téléchargés (cela s’applique principalement aux pages HTML).
wget \
https://fr.wikipedia.org/wiki/Orang-outan \
--directory-prefix=dossier-sur-les-orangs-outans
--output-document=page-wikipedia.html \
--adjust-extension \
--limit-rate=200k6.1 Archiver uniquement certains fichiers d’un site web
Télécharger uniquement les fichiers d’un format donné à partir d’un site web. L’option -c ou --continue permet de continuer un téléchargement interrompu.
wget https:/skhole.ecrituresnumeriques.ca/ \
-r \
-l2 \
-nd \
-A.mp3 \
-c \
-P archives-audio-skhole7. Archiver un site web au complet
Télécharger un site web au complet. (Attention : l’option --mirror n’est pas toujours autorisée.)
wget [URL] \
--mirror \
--convert-links \
--adjust-extension \
--page-requisites \
--no-parent \
--limit-rate=200k8. Conclusion
Nous espérons que vous avez compris l’utilité de l’outil wget et qu’il vous aidera à mettre en place vos propres stratégies d’archivage. Vous aurez compris à la lumière de cet atelier qu’il peut être judicieux de combiner wget avec un langage de programmation, comme python ou bash. Ce n’est qu’une pièce parmi tant d’autres dans votre boîte à outils !